
SEOはサイト全体でのプランニングが必要となっていますが、現状のmeta情報がどうなっているのかしっかり管理している必要があります。
その際に役立つmeta情報を一括でスクレイピングする方法をご紹介します。
Googleスプレッドシートでタイトルタグの抽出方法
Googleスプレッドシートにとっても便利な関数が存在します。
=IMPORTXML(URL, “//title”)
URL部分をセル番号にすることも可能なので
=IMPORTXML(セル番号, “//title”)
こちらで抽出可能。

このように、大量のURLのタイトルタグを抽出したい場合でも関数をひっぱれば取得可能です。
ただ、ひとつのスプレッドシートにスクレイピングのする数が多くなると、取得できない場合があるので、その場合は新しいスプレッドシートでわけて取得すると良いです◎
また、サイトによって、複数のタイトルタグが設置されている場合、うまく取得できない場合があります。その場合はINDEXタグと組み合わせると良いです。
=INDEX(IMPORTXML(セル番号,”//title”),1,1)
こうすると、複数のURLであっても1セルに収まりうまく取得できます。
ディスクリプションタグの抽出
ディスクリプションの場合は下記の記述で取得します。
=IMPORTXML(セル番号, “//meta[@name=’description’]/@content”)
複数行がある場合はこちらで対応可能◎
=INDEX(IMPORTXML(セル番号,”//meta[@name=’description’]/@content”),1,1)
下記サンプルです。
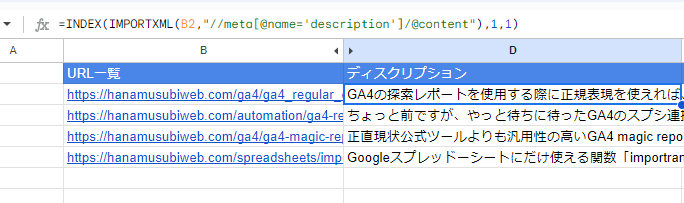
ディスクリプションが複数行にわたってしまうので、一行に収まるようにINDEXタグで調整してみました。
canonicalタグのスクレイピング方法
カノニカルタグの場合は下記の関数を使用します。
=IMPORTXML(セル番号,”//link[@rel=’canonical’]/@href”)
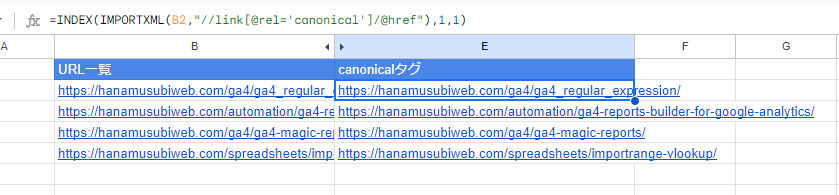
canonicalタグの中に入っているURLを抽出することができます!
これでB列とE列が同一かどうかも一括で関数で処理できるので、エラーを発見しやすくなります。
まとめ
タイトル・ディスクリプション・カノニカルを一覧に一気に取得

こんなかんじで管理することが可能です。またスプレッドシート関数の利点は
サイト側の更新があった際に手を動かす必要がないことです。
いちいち管理シートの更新をかけずに済むことも利点です。
スクレイピングの関数を利用して、ぜひSEOを捗らせてみてください。


コメント